
!wget -nc --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/2021.deeplearning/main/content/init.py
import init; init.init(force_download=False);/content/init.py:2: SyntaxWarning: invalid escape sequence '\S'
course_id = '\S*deeplearning\S*'
replicating local resources
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from IPython.display import Image
%matplotlib inline
import tensorflow as tf
tf.__version__forward/back propagation calculations https://medium.com/14prakash/back-propagation-is-very-simple-who-made-it-complicated-97b794c97e5c
Vanishing gradient example: Vanishing
https://
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tensorflow import keras
%matplotlib inlineVisualizing and understanding vanishing gradients¶
Make sure you understand well the backpropagation algorithm. You may perform by hand the calculations as illustrated here to consolidate your understanding.
We will be using three activation functions. Observe under which what values each function’s gradient becomes negligible (very near zero)
z = np.linspace(-10,10,100)
sigm = lambda z: 1/(1+np.exp(-z))
dsigm = lambda z: sigm(z)*(1-sigm(z))
plt.plot(z, sigm(z), lw=5, label="sigm")
plt.plot(z, dsigm(z), lw=5, label="grad sigm")
plt.grid()
plt.axvline(0, color="black");
plt.axhline(0, color="black");
plt.legend()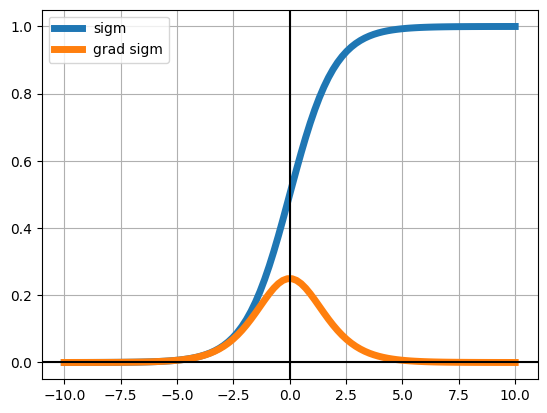
z = np.linspace(-10,10,100)
tanh = lambda z: (np.exp(z)-np.exp(-z))/(np.exp(z)+np.exp(-z))
dtanh = lambda z: 1 - tanh(z)**2
plt.plot(z, tanh(z), lw=5, label="tanh")
plt.plot(z, dtanh(z), lw=5, label="grad tanh")
plt.grid()
plt.axvline(0, color="black");
plt.axhline(0, color="black");
plt.legend()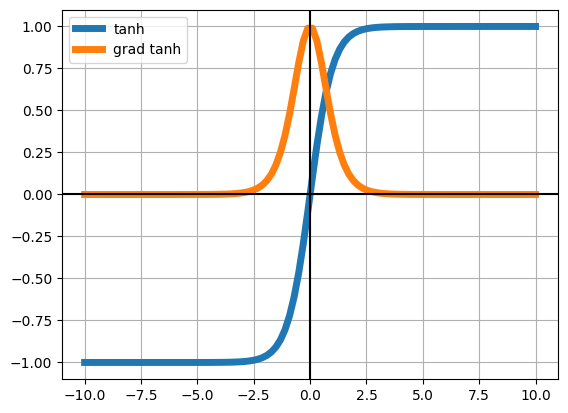
z = np.linspace(-2,2,100)
relu = np.vectorize(lambda z: z if z>0 else 0.)
drelu = np.vectorize(lambda z: 1 if z>0 else 0.)
plt.plot(z, relu(z), lw=5, label="relu")
plt.plot(z, drelu(z), lw=5, label="grad relu")
plt.grid()
plt.axvline(0, color="black");
plt.axhline(0, color="black");
plt.legend()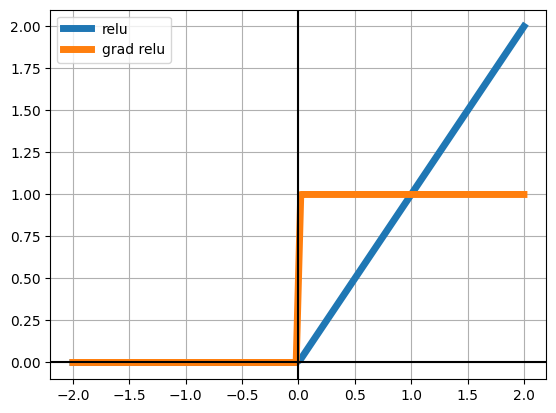
z = np.linspace(-2,2,100)
relu = np.vectorize(lambda z: z if z>0 else .1*z)
drelu = np.vectorize(lambda z: 1 if z>0 else .1)
plt.plot(z, relu(z), lw=5, label="relu")
plt.plot(z, drelu(z), lw=5, label="grad relu")
plt.grid();
plt.axvline(0, color="black");
plt.axhline(0, color="black");
plt.legend()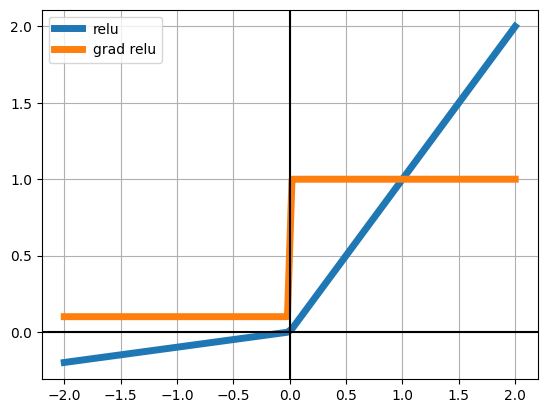
load sample MNIST data as customary¶
mnist = pd.read_csv("local/data/mnist1.5k.csv.gz", compression="gzip", header=None).values
X=mnist[:,1:785]/255.
y=mnist[:,0]
print("dimension de las imagenes y las clases", X.shape, y.shape)dimension de las imagenes y las clases (1500, 784) (1500,)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2)
X_train = X_train
X_test = X_test
y_train_oh = np.eye(10)[y_train]
y_test_oh = np.eye(10)[y_test]
print(X_train.shape, y_train_oh.shape)(1200, 784) (1200, 10)
from tensorflow.keras import Sequential, Model
from tensorflow.keras.layers import Dense, Dropout, Flatten, concatenate, Input
from tensorflow.keras.backend import clear_session
from tensorflow import kerasA basic multi layered dense model¶
observe that the function allows us to parametrize the number of hidden layers and their activation function
!rm -rf log
def get_model(input_dim=784, output_dim=10, num_hidden_layers=6, hidden_size=10, activation="relu"):
model = Sequential()
model.add(Dense(hidden_size, activation=activation, input_dim=input_dim, name="Layer_%02d_Input"%(0)))
for i in range(num_hidden_layers):
model.add(Dense(hidden_size, activation=activation, name="Layer_%02d_Hidden"%(i+1)))
model.add(Dense(output_dim, activation="softmax", name="Layer_%02d_Output"%(num_hidden_layers+1)))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return modelSIGMOID activation¶
model = get_model(num_hidden_layers=10, activation="sigmoid")
!rm -rf log/sigmoid
tb_callback = keras.callbacks.TensorBoard(log_dir='./log/sigmoid', histogram_freq=1, write_graph=True, write_images=True)
model.fit(X_train, y_train_oh, epochs=30, batch_size=32, validation_data=(X_test, y_test_oh), callbacks=[tb_callback])/usr/local/lib/python3.12/dist-packages/keras/src/layers/core/dense.py:93: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
Epoch 1/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 5s 23ms/step - accuracy: 0.1054 - loss: 2.3731 - val_accuracy: 0.1067 - val_loss: 2.3696
Epoch 2/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 2s 13ms/step - accuracy: 0.1028 - loss: 2.3353 - val_accuracy: 0.1067 - val_loss: 2.3355
Epoch 3/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.0926 - loss: 2.3204 - val_accuracy: 0.1067 - val_loss: 2.3203
Epoch 4/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.1052 - loss: 2.3042 - val_accuracy: 0.1233 - val_loss: 2.3130
Epoch 5/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.1037 - loss: 2.3028 - val_accuracy: 0.1233 - val_loss: 2.3093
Epoch 6/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1215 - loss: 2.3017 - val_accuracy: 0.1233 - val_loss: 2.3053
Epoch 7/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1330 - loss: 2.2979 - val_accuracy: 0.1233 - val_loss: 2.3039
Epoch 8/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.1190 - loss: 2.3007 - val_accuracy: 0.1233 - val_loss: 2.3030
Epoch 9/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1241 - loss: 2.2997 - val_accuracy: 0.1233 - val_loss: 2.3019
Epoch 10/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.1261 - loss: 2.2991 - val_accuracy: 0.1233 - val_loss: 2.3024
Epoch 11/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1299 - loss: 2.2960 - val_accuracy: 0.1233 - val_loss: 2.3018
Epoch 12/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1386 - loss: 2.2974 - val_accuracy: 0.1233 - val_loss: 2.3017
Epoch 13/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.1185 - loss: 2.2999 - val_accuracy: 0.1233 - val_loss: 2.3021
Epoch 14/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 20ms/step - accuracy: 0.1196 - loss: 2.2992 - val_accuracy: 0.1233 - val_loss: 2.3008
Epoch 15/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 19ms/step - accuracy: 0.1262 - loss: 2.2959 - val_accuracy: 0.1233 - val_loss: 2.3022
Epoch 16/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 18ms/step - accuracy: 0.1383 - loss: 2.2975 - val_accuracy: 0.1233 - val_loss: 2.3000
Epoch 17/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.1224 - loss: 2.3021 - val_accuracy: 0.1233 - val_loss: 2.3014
Epoch 18/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1309 - loss: 2.2959 - val_accuracy: 0.1233 - val_loss: 2.3023
Epoch 19/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1255 - loss: 2.2970 - val_accuracy: 0.1233 - val_loss: 2.3013
Epoch 20/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1314 - loss: 2.2937 - val_accuracy: 0.1233 - val_loss: 2.3016
Epoch 21/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1175 - loss: 2.2988 - val_accuracy: 0.1233 - val_loss: 2.3016
Epoch 22/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.1213 - loss: 2.2989 - val_accuracy: 0.1233 - val_loss: 2.3007
Epoch 23/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.1429 - loss: 2.2939 - val_accuracy: 0.1233 - val_loss: 2.3005
Epoch 24/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1247 - loss: 2.2984 - val_accuracy: 0.1233 - val_loss: 2.3018
Epoch 25/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.1363 - loss: 2.2947 - val_accuracy: 0.1233 - val_loss: 2.3022
Epoch 26/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1287 - loss: 2.2956 - val_accuracy: 0.1233 - val_loss: 2.3010
Epoch 27/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1320 - loss: 2.2975 - val_accuracy: 0.1233 - val_loss: 2.3010
Epoch 28/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1205 - loss: 2.3009 - val_accuracy: 0.1233 - val_loss: 2.3007
Epoch 29/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.1338 - loss: 2.2950 - val_accuracy: 0.1233 - val_loss: 2.3016
Epoch 30/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.1216 - loss: 2.2993 - val_accuracy: 0.1233 - val_loss: 2.3011
<keras.src.callbacks.history.History at 0x7f3615ceb3b0>RELU activation¶
model = get_model(num_hidden_layers=10, activation="relu")
!rm -rf log/relu
tb_callback = keras.callbacks.TensorBoard(log_dir='./log/relu', histogram_freq=1, write_graph=True, write_images=True)
model.fit(X_train, y_train_oh, epochs=30, batch_size=32, validation_data=(X_test, y_test_oh), callbacks=[tb_callback])Epoch 1/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 4s 20ms/step - accuracy: 0.0761 - loss: 2.3020 - val_accuracy: 0.1467 - val_loss: 2.2875
Epoch 2/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.1180 - loss: 2.2585 - val_accuracy: 0.2067 - val_loss: 2.1309
Epoch 3/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2003 - loss: 2.0828 - val_accuracy: 0.2200 - val_loss: 2.0145
Epoch 4/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2092 - loss: 1.9246 - val_accuracy: 0.2000 - val_loss: 1.9175
Epoch 5/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.2034 - loss: 1.8308 - val_accuracy: 0.2167 - val_loss: 1.8493
Epoch 6/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2405 - loss: 1.7564 - val_accuracy: 0.2733 - val_loss: 1.7784
Epoch 7/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2829 - loss: 1.6109 - val_accuracy: 0.3433 - val_loss: 1.7027
Epoch 8/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.3451 - loss: 1.4697 - val_accuracy: 0.3833 - val_loss: 1.6274
Epoch 9/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.4028 - loss: 1.3674 - val_accuracy: 0.4367 - val_loss: 1.6473
Epoch 10/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.3966 - loss: 1.3169 - val_accuracy: 0.4067 - val_loss: 1.6630
Epoch 11/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 18ms/step - accuracy: 0.4123 - loss: 1.2316 - val_accuracy: 0.4367 - val_loss: 1.6200
Epoch 12/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 18ms/step - accuracy: 0.4763 - loss: 1.1386 - val_accuracy: 0.5067 - val_loss: 1.7163
Epoch 13/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 22ms/step - accuracy: 0.5058 - loss: 1.1010 - val_accuracy: 0.4967 - val_loss: 1.6629
Epoch 14/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.5511 - loss: 1.0193 - val_accuracy: 0.4967 - val_loss: 1.6722
Epoch 15/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.5650 - loss: 1.0143 - val_accuracy: 0.5200 - val_loss: 1.5476
Epoch 16/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.5950 - loss: 0.9485 - val_accuracy: 0.5200 - val_loss: 1.6630
Epoch 17/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6264 - loss: 0.9099 - val_accuracy: 0.5267 - val_loss: 1.6491
Epoch 18/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.5965 - loss: 0.9193 - val_accuracy: 0.5633 - val_loss: 1.5708
Epoch 19/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6360 - loss: 0.8918 - val_accuracy: 0.5200 - val_loss: 1.6918
Epoch 20/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.6560 - loss: 0.8420 - val_accuracy: 0.5567 - val_loss: 1.6657
Epoch 21/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6177 - loss: 0.9001 - val_accuracy: 0.5700 - val_loss: 1.7047
Epoch 22/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.6718 - loss: 0.8106 - val_accuracy: 0.5767 - val_loss: 1.7745
Epoch 23/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6374 - loss: 0.8486 - val_accuracy: 0.5800 - val_loss: 1.6881
Epoch 24/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6945 - loss: 0.7626 - val_accuracy: 0.6133 - val_loss: 1.6876
Epoch 25/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.7263 - loss: 0.7405 - val_accuracy: 0.5833 - val_loss: 1.7602
Epoch 26/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7265 - loss: 0.7421 - val_accuracy: 0.6100 - val_loss: 1.8384
Epoch 27/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.7126 - loss: 0.7803 - val_accuracy: 0.6033 - val_loss: 1.8377
Epoch 28/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7535 - loss: 0.7120 - val_accuracy: 0.5967 - val_loss: 1.8472
Epoch 29/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.7638 - loss: 0.6707 - val_accuracy: 0.6133 - val_loss: 1.9387
Epoch 30/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7216 - loss: 0.7566 - val_accuracy: 0.6233 - val_loss: 1.8856
<keras.src.callbacks.history.History at 0x7f35edb6ab10>Leaky RELU activation¶
import tensorflow as tf
model = get_model(num_hidden_layers=10, activation=tf.nn.leaky_relu)
!rm -rf log/leaky_relu
tb_callback = keras.callbacks.TensorBoard(log_dir='./log/leaky_relu', histogram_freq=1, write_graph=True, write_images=True)
model.fit(X_train, y_train_oh, epochs=30, batch_size=32, validation_data=(X_test, y_test_oh), callbacks=[tb_callback])Epoch 1/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 4s 21ms/step - accuracy: 0.1153 - loss: 2.3002 - val_accuracy: 0.1833 - val_loss: 2.2727
Epoch 2/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2004 - loss: 2.2264 - val_accuracy: 0.2167 - val_loss: 2.0627
Epoch 3/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.2128 - loss: 2.0220 - val_accuracy: 0.2200 - val_loss: 2.0331
Epoch 4/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.2566 - loss: 1.8607 - val_accuracy: 0.2667 - val_loss: 1.8322
Epoch 5/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.3321 - loss: 1.6833 - val_accuracy: 0.2867 - val_loss: 1.7486
Epoch 6/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.3403 - loss: 1.5454 - val_accuracy: 0.3200 - val_loss: 1.6454
Epoch 7/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.3849 - loss: 1.4163 - val_accuracy: 0.3333 - val_loss: 1.5965
Epoch 8/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.3988 - loss: 1.3185 - val_accuracy: 0.3500 - val_loss: 1.6274
Epoch 9/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.4312 - loss: 1.2683 - val_accuracy: 0.4733 - val_loss: 1.4862
Epoch 10/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.5286 - loss: 1.1724 - val_accuracy: 0.4267 - val_loss: 1.6519
Epoch 11/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 17ms/step - accuracy: 0.5403 - loss: 1.1548 - val_accuracy: 0.4767 - val_loss: 1.5348
Epoch 12/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 21ms/step - accuracy: 0.6052 - loss: 1.0305 - val_accuracy: 0.4767 - val_loss: 1.5166
Epoch 13/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 20ms/step - accuracy: 0.6104 - loss: 0.9848 - val_accuracy: 0.5367 - val_loss: 1.4080
Epoch 14/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6407 - loss: 0.9210 - val_accuracy: 0.4900 - val_loss: 1.6197
Epoch 15/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.6302 - loss: 0.8917 - val_accuracy: 0.5100 - val_loss: 1.7791
Epoch 16/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.6345 - loss: 0.9043 - val_accuracy: 0.6100 - val_loss: 1.3989
Epoch 17/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.6641 - loss: 0.8482 - val_accuracy: 0.5733 - val_loss: 1.5803
Epoch 18/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7033 - loss: 0.7594 - val_accuracy: 0.5500 - val_loss: 1.5795
Epoch 19/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7261 - loss: 0.7307 - val_accuracy: 0.6167 - val_loss: 1.5252
Epoch 20/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7317 - loss: 0.7193 - val_accuracy: 0.6167 - val_loss: 1.6626
Epoch 21/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.8123 - loss: 0.5962 - val_accuracy: 0.6033 - val_loss: 1.8928
Epoch 22/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7938 - loss: 0.6043 - val_accuracy: 0.6000 - val_loss: 1.8191
Epoch 23/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.7695 - loss: 0.6307 - val_accuracy: 0.6100 - val_loss: 1.8240
Epoch 24/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.7817 - loss: 0.6184 - val_accuracy: 0.6267 - val_loss: 1.7866
Epoch 25/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.8311 - loss: 0.5729 - val_accuracy: 0.6567 - val_loss: 1.8094
Epoch 26/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.8459 - loss: 0.4978 - val_accuracy: 0.5933 - val_loss: 2.1872
Epoch 27/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.8579 - loss: 0.4858 - val_accuracy: 0.6567 - val_loss: 2.0357
Epoch 28/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.8561 - loss: 0.4508 - val_accuracy: 0.6367 - val_loss: 2.2305
Epoch 29/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.8440 - loss: 0.4778 - val_accuracy: 0.6400 - val_loss: 2.1412
Epoch 30/30
38/38 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.8460 - loss: 0.4737 - val_accuracy: 0.6367 - val_loss: 2.0085
<keras.src.callbacks.history.History at 0x7f360e0ccec0>SIGMOID activation but longer run (epochs)¶
model = get_model(num_hidden_layers=10, activation="sigmoid")
!rm -rf log/sigmoid_longrun
tb_callback = keras.callbacks.TensorBoard(log_dir='./log/sigmoid_longrun', histogram_freq=1, write_graph=True, write_images=True)
model.fit(X_train, y_train_oh, epochs=300, batch_size=32, validation_data=(X_test, y_test_oh), callbacks=[tb_callback])<tensorflow.python.keras.callbacks.History at 0x7fb4259a4550>Experiment observations, on Tensorboard¶
What is the distribution of the weights observed as we move from the output layer to the input layer for each experiment?
Look in Tensorboard at distributions or histograms charts named
Layer_00_Input/kernel_0,Layer_01_Hidden/kernel_0, etc. for different layers. You should see:Gradients are usually higher at the output layer and tend to decrease as you move backwards in the network.
With sigmoid activations gradients are always low and rapidly decay from the output layer all the way to the input layer.
Relu might still have some vanishing gradient when weights are <0.
Leaky Relu would probably have constant gradients across layers.
Recall that, in the backpropagation algorithm, the gradient of the loss function with respect to the weights at a certain layer is proportional to the derivatives and the weights of previous layers:
where is the derivative of the activation function and is the output at layer .
Do you think the sigmoid longrun would reach levels comparable to Relu or Leaky Relu? At what computational cost?
%load_ext tensorboard
%tensorboard --logdir log