Matrices dispersas
Contents
Matrices dispersas¶
!wget -nc --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/introalgs.v1/main/content/init.py
import init; init.init(force_download=False);
Objetivo del módulo¶
Conocer lo que son matrices dispersas (sparse) y su representación y manipulación en tripletas.
Preguntas básicas¶
¿Qué es una matriz dispersa?
¿Qué tupos eficiencia se pueden explotar por su dispersión?
¿En qué complejidades computacionales incurrimos en sus distintas operaciones?
¿Qué compromisos de eficiencia adquirimos cons distintas representaciones?
Introducción¶
En muchas ocasiones se presentan matrices en las cuales una gran cantidad de elementos son 0. Por ejemplo en sistemas de recomendación se usan matrices para representar las preferencias de millones de usuarios a millones de productos. En realidad, normalmente cada usuario valora o usa un conjunto muy pequeño de todos los productos disponibles y la matriz resultante tiene muchos ceros.
from IPython.display import Image
Image(filename='local/imgs/recommender_matrix.jpg', width=400)

Normalmente se busca una economía de memoria en las estructuras de datos para almacenar únicamente las posiciones de la matriz con valor distinto de cero. Pero esto implica adaptar los algoritmos a dichas estructuras de datos.
Una métrica de dispersión (sparness metric) cuantifica el grado de dispersión de una matriz. P.ej.
en el caso de la figura anterior: \(17/36 = 0.47\)
Usaremos la siguiente clase para almacenar cada elemento con sus coordenadas en una matriz.
class Triplet:
def __init__(self, row, col, val):
assert isinstance(row, int) and isinstance(col, int) and row>=0 and col>=0
self.row = row
self.col = col
self.val = val
def __repr__(self):
return "[%d %d] = %s"%(self.row, self.col, str(self.val))
t = Triplet(2,4,20.3)
t
[2 4] = 20.3
clase SparseMatrix: realizamos una clase que representa una matriz como una lista de tripletas, con las operaciones correspondientes sobre dicha lista.
import itertools
class SparseMatrix:
def __init__(self, m=None):
self.triplets = []
self.shape = m.shape if m is not None else (0,0)
if m is not None:
for i,j in itertools.product(list(range(m.shape[0])), list(range(m.shape[1]))):
if m[i,j]!=0:
self.triplets.append(Triplet(i,j,m[i,j]))
def to_dense(self):
r = np.zeros(self.shape)
for t in self.triplets:
r[t.row, t.col] = t.val
return r
def sparseness_metric(self):
return len(self.triplets) *1./(self.shape[0]*self.shape[1])
def __getitem__(self, pos):
i,j = pos
for t in self.triplets:
if t.row==i and t.col==j:
return t.val
return 0
def __setitem__(self, pos, val):
i,j = pos
if val==0:
return
for t in self.triplets:
if t.row==i and t.col==j:
t.val=val
return
self.triplets.append(Triplet(i,j,val))
self.shape = (np.max([self.shape[0], i+1]), np.max([self.shape[1], j+1]))
def __add__(self, m):
r = self.__class__()
for t in m.triplets + self.triplets:
r[t.row, t.col] = r[t.row, t.col] + t.val
return r
def dot(self, m):
assert self.shape[0]==m.shape[1] and self.shape[1]==m.shape[0], "incorrect dimensions %s x %s"%(str(self.shape), str(m.shape))
r = self.__class__()
for t1 in self.triplets:
for t2 in m.triplets:
if t1.col==t2.row:
r[t1.row, t2.col] = r[t1.row, t2.col] + t1.val*t2.val
return r
def T(self):
r = self.__class__()
for t in self.triplets:
r[t.col, t.row] = t.val
return r
def __repr__(self):
return "shape = %s\ntriplets = %s"%(self.shape, self.triplets)
Algorítmica implementada¶
Operaciones básicas¶
fíjate cómo creamos una matriz dispersa como array de numpy de manera aleatoria
import numpy as np
def random_sparse_matrix(size):
m = np.random.randint(2, size=size)
m = m * np.random.randint(10,size=size)
return m
m = random_sparse_matrix((5,3))
print(m.shape)
m
(5, 3)
array([[0, 8, 0],
[0, 0, 3],
[5, 0, 0],
[7, 0, 9],
[0, 0, 0]])
creamos la matriz dispersa y la inspeccionamos
sm = SparseMatrix(m)
print(sm.sparseness_metric())
sm
0.3333333333333333
shape = (5, 3)
triplets = [[0 1] = 8, [1 2] = 3, [2 0] = 5, [3 0] = 7, [3 2] = 9]
print(sm.triplets)
[[0 1] = 8, [1 2] = 3, [2 0] = 5, [3 0] = 7, [3 2] = 9]
sm.to_dense().astype(int)
array([[0, 8, 0],
[0, 0, 3],
[5, 0, 0],
[7, 0, 9],
[0, 0, 0]])
y su transpuesta
sm.T().to_dense().astype(int)
array([[0, 0, 5, 7],
[8, 0, 0, 0],
[0, 3, 0, 9]])
Insercción y acceso.¶
Fíjate como en Python los métodos __getitem__ y __setitem__ son accesibles a partir de una sintaxis especial
print(sm.__getitem__((4,1)))
print(sm[4,1])
0
0
sm.__setitem__((4,1),17)
print(sm[4,1])
sm.to_dense().astype(int)
17
array([[ 0, 8, 0],
[ 0, 0, 3],
[ 5, 0, 0],
[ 7, 0, 9],
[ 0, 17, 0]])
sm[4,1]=2
print(sm[4,1])
sm.to_dense().astype(int)
2
array([[0, 8, 0],
[0, 0, 3],
[5, 0, 0],
[7, 0, 9],
[0, 2, 0]])
la siguiente operación llama a ambos métodos
sm[4,1] = sm[4,1]*2
sm.to_dense().astype(int)
array([[0, 8, 0],
[0, 0, 3],
[5, 0, 0],
[7, 0, 9],
[0, 4, 0]])
Adición¶
(sm+sm).to_dense().astype(int)
array([[ 0, 16, 0],
[ 0, 0, 6],
[10, 0, 0],
[14, 0, 18],
[ 0, 8, 0]])
sm1 = SparseMatrix(random_sparse_matrix((5,3)))
sm2 = SparseMatrix(random_sparse_matrix((3,2)))
print(sm1.to_dense())
print(sm2.to_dense())
[[6. 7. 0.]
[0. 0. 2.]
[7. 0. 0.]
[9. 0. 1.]
[0. 0. 0.]]
[[0. 0.]
[8. 0.]
[2. 0.]]
(sm1+sm2).to_dense()
array([[6., 7., 0.],
[8., 0., 2.],
[9., 0., 0.],
[9., 0., 1.]])
Multiplicación de matrices¶
Revisa Multiplicación de Matrices en Wikipedia si no te acuerdas cómo es esta operación
m1 = np.random.randint(10, size=(3,2))
print(m1)
m2 = np.random.randint(10, size=(2,3))
print(m2)
print("--")
print(m1.dot(m2))
print(SparseMatrix(m1).dot(SparseMatrix(m2)).to_dense().astype(int))
print("--")
print(m2.dot(m1))
print(SparseMatrix(m2).dot(SparseMatrix(m1)).to_dense().astype(int))
[[7 4]
[7 0]
[7 3]]
[[7 7 9]
[9 8 6]]
--
[[85 81 87]
[49 49 63]
[76 73 81]]
[[85 81 87]
[49 49 63]
[76 73 81]]
--
[[161 55]
[161 54]]
[[161 55]
[161 54]]
Análisis de complejidad computacional¶
creamos una función para que nos devuelva una matriz con elementos aleatorios
def random_sparse_matrix(max_rows, max_cols, n_items):
m = SparseMatrix()
for _ in range(n_items):
i = np.random.randint(max_rows)
j = np.random.randint(max_cols)
v = np.random.randint(100)
m[i,j] = v
return m
k=random_sparse_matrix(1000,1000,1000)
k.shape, k.sparseness_metric()
((1000, 999), 0.000990990990990991)
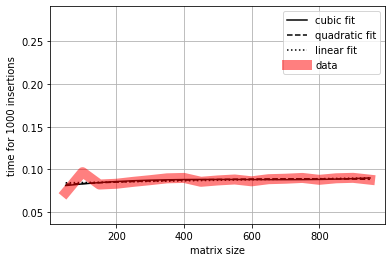
### __setitem__: según el tamaño de las matrices
Fíjate cómo montamos un experimento con %timeit. El experimento sugiere que el tiempo de ejecución no depende del tamaño de las matrices.
r1 = []
n1 = range(50,1000,50)
for n in n1:
print (n, end=" ")
k = %timeit -o -q -r 3 -n 3 random_sparse_matrix(n,n,1000)
r1.append(k.best)
50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 950
import matplotlib.pyplot as plt
%matplotlib inline
def plot_times(n_set, r, xlabel, ylabel):
from scipy.optimize import minimize
n_set = np.array(n_set)
# fit to scaled for numerical stability
x_ticks = n_set/1e3
r = np.array(r)
cfunc = lambda k, x: k[0]+k[1]*x+k[2]*x**2+k[3]*x**3
qfunc = lambda k, x: k[0]+k[1]*x+k[2]*x**2
lfunc = lambda k, x: k[0]+k[1]*x
ccost = lambda k: np.mean( (r-cfunc(k, x_ticks))**2)
qcost = lambda k: np.mean( (r-qfunc(k, x_ticks))**2)
lcost = lambda k: np.mean( (r-lfunc(k, x_ticks))**2)
cx = minimize(ccost, [0,0,0,0], method="BFGS").x
qx = minimize(qcost, [0,0,0], method="BFGS").x
lx = minimize(lcost, [0,0], method="BFGS").x
plt.plot(x_ticks*1e3, cfunc(cx, x_ticks), label="cubic fit", color="black")
plt.plot(x_ticks*1e3, qfunc(qx, x_ticks), label="quadratic fit", color="black", ls="--")
plt.plot(x_ticks*1e3, lfunc(lx, x_ticks), label="linear fit", color="black", ls=":")
plt.plot(x_ticks*1e3, r, label="data", lw=10, alpha=.5, color="red")
plt.legend()
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.grid()
plot_times(n1, r1, xlabel="matrix size", ylabel="time for 1000 insertions")
plt.ylim(np.min(r1)/2, np.max(r1)*3);
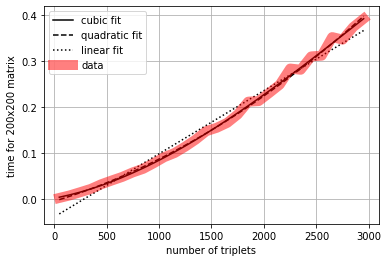
__setitem__: según el número de elementos insertados¶
El experimento sugiere una complejidad \(\mathcal{O}(n^2)\). Observa el método __setitem__. En el peor de los casos, para insertar un elemento hay que recorrer toda la lista de tripletas. Por tanto, si \(n\) es el número de tripletas, y para insertar cada elemento hay que hacer un bucle (\(\mathcal{O}(n)\)), para \(n\) elementos la complejidad es \(\mathcal{O}(n ^2)\)
r2 = []
n2 = range(50,3000,100)
for n in n2:
print (n, end=" ")
k = %timeit -o -q -r 3 -n 3 random_sparse_matrix(200,200,n)
r2.append(k.best)
50 150 250 350 450 550 650 750 850 950 1050 1150 1250 1350 1450 1550 1650 1750 1850 1950 2050 2150 2250 2350 2450 2550 2650 2750 2850 2950
plot_times(n2, r2, xlabel="number of triplets", ylabel="time for 200x200 matrix")
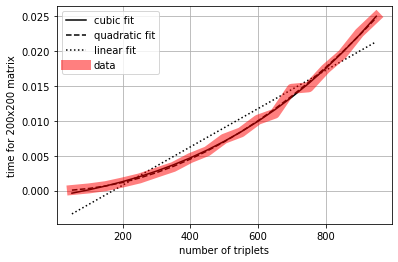
__getitem__: según el número de tripletas¶
El experimento sugiere una complejidad \(\mathcal{O}(n^2)\). Analiza el resultado con un argumento similar al anterior. Fíjate que __setitem__ tiene la misma complejidad pero tarda más. Las complejidades tienen el mismo orden de magnitud (\(n^2\)), pero difieren en una constante.
r1 = []
n1 = range(50,1000,50)
def getn(m,n):
for t in m.triplets:
m[t.row, t.col]
for n in n1:
print (n, end=" ")
m = random_sparse_matrix(200,200,n)
k = %timeit -o -q -r 3 -n 3 getn(m,n)
r1.append(k.best)
50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800 850 900 950
plot_times(n1, r1, xlabel="number of triplets", ylabel="time for 200x200 matrix")
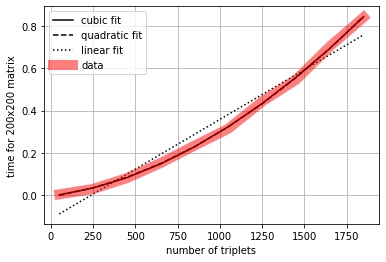
__add__: según el número de tripletas¶
El experimento sugiere una complejidad \(\mathcal{O}(n^2)\), asumiendo que ambas matrices tienen el mismo número de tripletas. Observa que el método __add__ realiza un __getitem__ y un __setitem__ por cada elemento de cada matriz:
for t in m.triplets + self.triplets:
r[t.row, t.col] = r[t.row, t.col] + t.val
Por tanto, la complejidad es en realidad \(\mathcal{O}( 2n\times (n+n) ) = k \mathcal{O}(n^2)\) en donde:
\(2n\) es por el bucle por ambas matrices
\(n+n\) es por el
__getitem__y por el__setitem__
r3 = []
n3 = range(50,2000,200)
for n in n3:
print (n, end=" ")
m1 = random_sparse_matrix(200,200,n)
m2 = random_sparse_matrix(200,200,n)
k = %timeit -o -q -r 1 -n 1 m1+m2
r3.append(k.best)
50 250 450 650 850 1050 1250 1450 1650 1850
plot_times(n3, r3,xlabel="number of triplets", ylabel="time for 200x200 matrix")
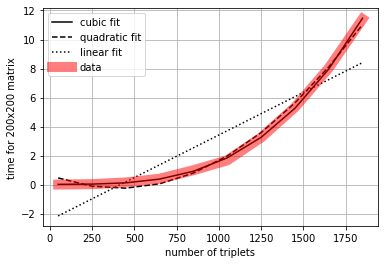
dot: según el número de triplets¶
El experimento sugiere una complejidad \(\mathcal{O}(n^3)\). Observa el método dot. De nuevo, en el peor de los casos, por cada elemento tiene que realizar un bucle anidado, es decir \(n^2\) iteraciones. Por tanto, con \(n\) elementos tenemos \(\mathcal{O}(n^3)\). Fíjate que el fit cúbico (\(n^3\)) se ajusta mejor que el cuadrático (\(n^2\)). Igualmente restringimos el valor máximo de \(n\) en el experimento precisamente por que esta complejidad mayor hace que se demore más.
r4 = []
n4 = range(50,2000,200)
for n in n4:
print (n, end=" ")
m = random_sparse_matrix(200,200,n)
k = %timeit -o -q -r 1 -n 1 m.dot(m.T())
r4.append(k.best)
50 250 450 650 850 1050 1250 1450 1650 1850
plot_times(n4, r4,xlabel="number of triplets", ylabel="time for 200x200 matrix")
Preguntas y ejercicios propuestos¶
¿cómo hacer la implementación más eficiente en get? ¿almacenando las tripletas como un diccionario? ¿almacenando un diccionario de filas y otro de columnas?
Python tiene una librería para tratar con matrices dispersas
scipy.sparse, consúltala y experimenta con ella.Elabore algoritmo para intercambiar dos filas de una matriz representada en tripletas.
Elabore algoritmo para intercambiar dos columnas en una matriz representada en tripletas.
Elabore algoritmo que multiplique dos matrices representadas en tripletas.
Elabore algoritmo que determine si una matriz representada en tripletas tiene punto de silla o no. Su algoritmo debe escribir el punto de silla y retornar verdadero si la matriz tiene punto de silla, de lo contrario debe retornar falso. Si existe, un punto de silla es el elemento (tripleta) que es el menor valor de su fila, y a la vez el mayor de su columna.
Elabore algoritmo que determine si una matriz representada en tripletas es simétrica o no. Su algoritmo debe retornar verdadero si la matriz es simétrica, falso de lo contrario.