
LAB 5.2 - Padding - Masking#
!wget -nc --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/2021.deeplearning/main/content/init.py
import init; init.init(force_download=False); init.get_weblink()
from local.lib.rlxmoocapi import submit, session
import inspect
session.LoginSequence(endpoint=init.endpoint, course_id=init.course_id, lab_id="L05.02", varname="student");
#Basic required libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
The aim of this lab is to build a system for sentiment analysis on a dataset of tweets.#
The data consist on passenger’s reviews of U.S. airlines: https://www.kaggle.com/crowdflower/twitter-airline-sentiment
data = pd.read_csv('local/data/Tweets.csv')
# Keeping only the neccessary columns
data = data[['text','airline_sentiment']]
data
import re
# Remove neutral class
data = data[data["airline_sentiment"] != "neutral"].copy()
# Text normalization (vectorized, no iterrows)
data["text"] = (
data["text"]
.str.lower() # lowercase
.str.replace(r"@[^\s]+", "", regex=True) # remove @user mentions
.str.replace(r"[^a-zA-Z0-9\s]", "", regex=True) # remove punctuation/symbols
.str.replace(r"\brt\b", " ", regex=True) # remove 'rt'
)
# Count samples
Np = np.sum(data["airline_sentiment"].values == "positive")
Nn = np.sum(data["airline_sentiment"].values == "negative")
print(f"Number of positive samples = {Np}")
print(f"Number of negative samples = {Nn}")
data
import nltk
nltk.download('punkt_tab')
nltk.download('stopwords')
# Removing Stop Words
from nltk.corpus import stopwords
all_sentences = data['text'].values
all_words = [nltk.word_tokenize(sent) for sent in all_sentences]
stop_words = stopwords.words('english')
stop_words.append('')
for i in range(len(all_words)):
all_words[i] = [w for w in all_words[i] if (w not in stop_words) and (not w.isdigit())]
Task 1#
all_words is a list with all the tweets that are going to be used to train the model. Create a function ‘get_preprocessed_seq’ that build and apply a Tokenizer to the a list like all_words. Tokenizer must define a dictionary of 2000 words (remeber that position 0 is reserved). Once the sentences are tokenized, take into account that the length of every tweet is different so before they can be passed to the training step, the tweets must be padded in order to provide them with equal length. The function ‘get_preprocessed_seq’ must return the Tokenizer object and the padded dataset.
Review the padding function in the preprocessing module of keras.
def get_preprocessed_seq(text_list):
...
return tokenizer, Xdata
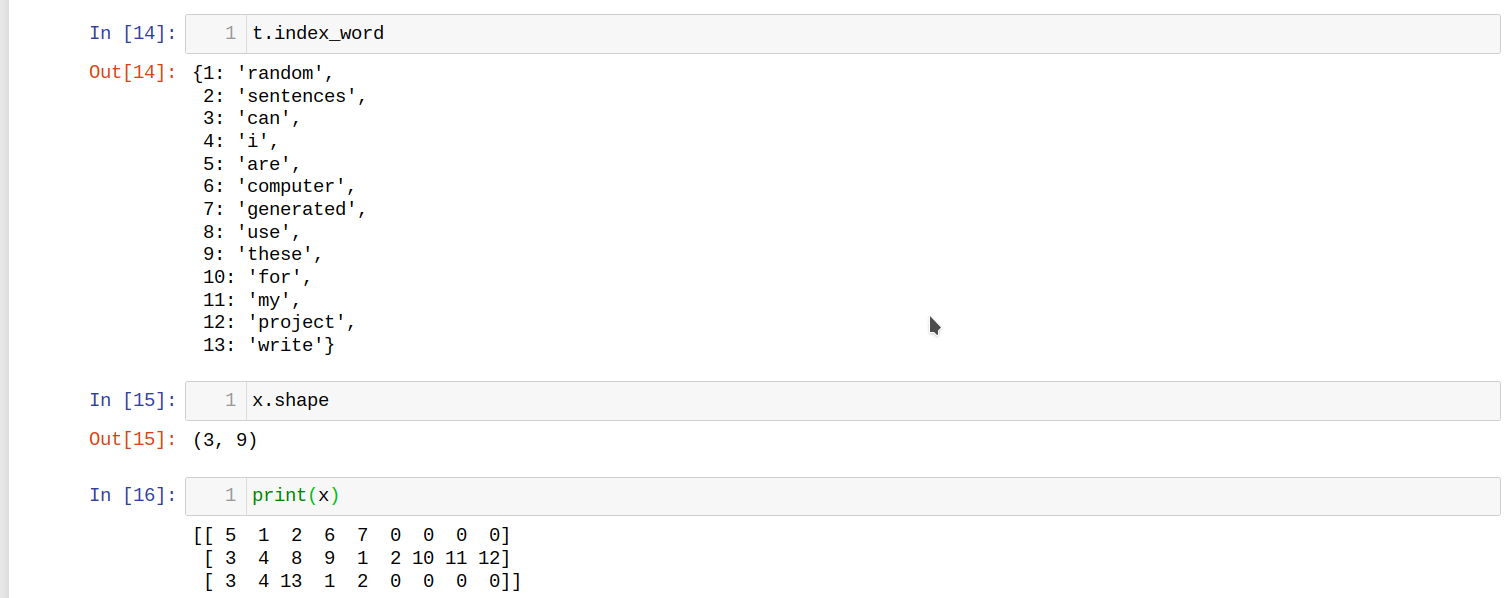
Test your function:
text_list = ['Are random sentences computer generated?',
'Can I use these random sentences for my project?',
'Can I write random sentences?']
t,x = get_preprocessed_seq(text_list)
You should get the following results:
from IPython.display import Image
Image(filename='local/imgs/tokenizer_padding.png', width=600)
Submit your solution:
student.submit_task(namespace=globals(), task_id='T1');
Task 2#
The previous step add 0’s to some tweets in order to set them with the same length. Now it is necessary to define a model that be able to discard those 0’s. Review the masking layer and masking option of the embedding layer of keras. Take a look to the TensorFlow documentation.
Create a function to define a RNN architecture for the sentiment analysis problem. Use the Embedding layer and its masking option to discard the 0’s added during padding step. The architecture must consist of a RNN layer with a ‘cells_number’ of neurons, a dense hidden layer of 10 neurons and the output layer. Include a Dropout layer in between the dense layers with a drop rate of 0.3 . The type of RNN layer must be defined through a ‘layer_type’ parameter; the embedding dimension must also be set as an input parameter. The activation function for ‘SimpleRNN’ must be set to ‘relu’, while for LSTM and GRU a default ‘tanh’ must be chosen instead.
def Recurrent_Model(cells_number = 10, layer_type='SimpleRNN',Embeb_dim=32):#Options for layer_type: 'SimpleRNN', 'LSTM', 'GRU'
model = ...
return model
Submit your solution:
student.submit_task(namespace=globals(), task_id='T2');
Let’s test the model:#
Warning: Run this part only if you have already passed Tasks 1 and 2.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import recall_score, accuracy_score
from sklearn.utils.class_weight import compute_class_weight
tokenizer, NewX = get_preprocessed_seq(all_words)
y = data['airline_sentiment'].values
Encoder = LabelEncoder()
Y = Encoder.fit_transform(y)
#Y = Encoder.transform(y)
X_tr, X_te, y_tr, y_te = train_test_split(NewX, Y, test_size=0.2, random_state=2018)
def especi_score(y_te,y_pred):
Ns = np.sum(y_te == 0)
return np.sum(y_te[y_te == 0] == y_pred[y_te == 0])/Ns
sensitivity = np.zeros((3,3))
especificity = np.zeros((3,3))
accuracy = np.zeros((3,3))
for i, embed_dim in enumerate([32,64,128]):
for j,cells in enumerate([32,64,128]):
model = Recurrent_Model(cells_number= cells, layer_type='LSTM', Embeb_dim=embed_dim)
#opt = optimizers.Adam(learning_rate=0.0001, beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(optimizer='adam', loss="binary_crossentropy", metrics=["accuracy"])
model.fit(X_tr, y_tr, validation_split=0.1,batch_size=32, epochs=10, verbose=1)
y_pred = np.round(model.predict(X_te))
sensitivity[i,j] = recall_score(y_te,y_pred)
accuracy[i,j] = accuracy_score(y_te,y_pred)
especificity[i,j] = especi_score(y_te,y_pred.flatten())
from local.lib.DataPreparationRNN import Plot_sentiment_performance
Plot_sentiment_performance(sensitivity,accuracy,especificity)
Task 3#
Create a similar architecture to that of task 2, but in this case use pretrained global vectors (GloVe). Set the Embedding layer as non trainable. If there is any missing word in the pre-trained GloVes, you can use the token ‘unk’ instead.
Note: Take care on the tokenization of the words. Keras tokenizer does not assign the zero value to any word because of padding purposes. Make sure that the order of the vectors in the GloVe embedding matrix corresponds with the indexes in the dictionary.
The following cell downloads Glove; it takes some time to complete.
#Run this cell to get the pre-trained word embedding vectors
import requests, zipfile, io
# 1. Download the embeddings
url = "http://nlp.stanford.edu/data/glove.twitter.27B.zip"
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall("glove_twitter") # extract into folder
# 2. Load the 50-dim file
embeddings_index = {}
with open("glove_twitter/glove.twitter.27B.50d.txt", encoding="utf8") as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype="float32")
embeddings_index[word] = coefs
print("Loaded %s word vectors." % len(embeddings_index))
# Example
print(embeddings_index["hello"][:10])
def Recurrent_Model_TF(tokenizer,embeddings_index,cells_number = 10, layer_type='SimpleRNN'):#Options for layer_type: 'SimpleRNN', 'LSTM', 'GRU'
model = ...
return model
Submit your solution:
student.submit_task(namespace=globals(), task_id='T3');
Let’s test the model:#
Warning: Run this part only if you have already passed Tasks 2 and 3.
sensitivity = np.zeros((3))
especificity = np.zeros((3))
accuracy = np.zeros((3))
for j,cells in enumerate([32,64,128]):
model = Recurrent_Model_TF(tokenizer, embeddings_index, cells_number = cells, layer_type='LSTM')
model.compile(optimizer='adam', loss="binary_crossentropy", metrics=["accuracy"])
model.fit(X_tr, y_tr, validation_split=0.1,batch_size=32, epochs=10, verbose=1)
y_pred = np.round(model.predict(X_te))
sensitivity = recall_score(y_te,y_pred)
accuracy[j] = accuracy_score(y_te,y_pred)
especificity[j] = especi_score(y_te,y_pred.flatten())
fig, ax = plt.subplots(figsize=(5,3))
X = np.arange(3)
ax.bar(X + 0.00, accuracy, color = 'b', width = 0.25)
ax.bar(X + 0.25, sensitivity, color = 'g', width = 0.25)
ax.bar(X + 0.50, especificity, color = 'r', width = 0.25)
ax.set_xticks([0.25, 1.25, 2.25])
ax.set_xticklabels(['32','64', '128'])
ax.set_title('Performance')
ax.set_xlabel('Number of cells')
ax.legend(labels=['accuracy','sensitivity','especificity'],bbox_to_anchor=(1.1, 1.05))
print('Best accuracy= {}'.format(np.max(accuracy)))
Task 4#
Create a function similar to that of task 3, but use a Conv1D layer instead of the LSTM one. The output of the Conv1D layer must keep the dimension related to the number of words per sentence unchanged. The number of filters (kernels) must be a functions’ input parameter and define the kernels size in order for the model to use trigrams. Let the rest of parameters with their default values. Use the GloVe embedding weights from the former task. To complete the architecture and shape correctly the tensors, you must use a GlobalMaxPooling1D layer after the CNN layer.
def Con1D_Model_TF(tokenizer, embeddings_index, filters = 10):
...
return model
Submit your solution:
student.submit_task(namespace=globals(), task_id='T4');
Let’s test the model:#
Warning: Run this part only if you have already passed Tasks 3 and 4.
sensitivity = np.zeros((3))
especificity = np.zeros((3))
accuracy = np.zeros((3))
for j,cells in enumerate([6,12,24]):
model = Con1D_Model_TF(tokenizer, embeddings_index, filters = cells)
model.compile(optimizer='adam', loss="binary_crossentropy", metrics=["accuracy"])
model.fit(X_tr, y_tr, validation_split=0.1,batch_size=32, epochs=10, verbose=1)
y_pred = np.round(model.predict(X_te))
sensitivity = recall_score(y_te,y_pred)
accuracy[j] = accuracy_score(y_te,y_pred)
especificity[j] = especi_score(y_te,y_pred.flatten())
fig, ax = plt.subplots(figsize=(5,3))
X = np.arange(3)
ax.bar(X + 0.00, accuracy, color = 'b', width = 0.25)
ax.bar(X + 0.25, sensitivity, color = 'g', width = 0.25)
ax.bar(X + 0.50, especificity, color = 'r', width = 0.25)
ax.set_xticks([0.25, 1.25, 2.25])
ax.set_xticklabels(['6','12', '24'])
ax.set_title('Performance')
ax.set_xlabel('Number of filters')
ax.legend(labels=['accuracy','sensitivity','especificity'],bbox_to_anchor=(1.1, 1.05))
print('Best accuracy= {}'.format(np.max(accuracy)))