
5.4 Text processing#
!wget -nc --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/2021.deeplearning/main/content/init.py
import init; init.init(force_download=False);
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.__version__
'2.0.2'
There exists several applications that require the processing of text, e.g. machine translation, sentiment analysis, semantic word similarity, part of speech tagging, to name just a few. However, in order to solve those problems, the text needs to be transformed into something that can be understood by the models. In the following some of the basic preprocessing steps that must be applied to text are going to be presented.
Natural Language Toolkit https://www.nltk.org/index.html
NLTK is a platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
Tokenization#
This process assigns a unique number to every word (or character) in the dataset. Tokenization requires to set up the maximum number of fatures or words to be included in the tokenizer.
import nltk
nltk.download('punkt_tab')
from nltk import word_tokenize
text = 'ejemplo de texto a ser procesado'
word_tokenize(text)
[nltk_data] Downloading package punkt_tab to
[nltk_data] /Users/jdariasl/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
['ejemplo', 'de', 'texto', 'a', 'ser', 'procesado']
from tensorflow.keras.preprocessing.text import Tokenizer
text = 'ejemplo de texto a ser procesado ejemplo'
max_fatures = 8
tokenizer = Tokenizer(num_words=max_fatures, split=' ')
tokenizer.fit_on_texts([text])
tokenizer.word_index.update({'<pad>': 0})
X = tokenizer.texts_to_sequences([text])
print([text])
print(X)
['ejemplo de texto a ser procesado ejemplo']
[[1, 2, 3, 4, 5, 6, 1]]
#Dictionary
tokenizer.word_index
{'ejemplo': 1,
'de': 2,
'texto': 3,
'a': 4,
'ser': 5,
'procesado': 6,
'<pad>': 0}
If there are more unique words in the text than num_words, only the most frequent ones are given a unique token.
Depending on the task, it may be necessary to eliminate some words such as prepositions#
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words('spanish')
[nltk_data] Downloading package stopwords to
[nltk_data] /Users/jdariasl/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
def tokenize_only(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word.lower() for word in nltk.word_tokenize(text) if word not in stopwords]
return tokens
print(tokenize_only(text))
['ejemplo', 'texto', 'ser', 'procesado', 'ejemplo']
Document representations#
Bag of words#
The most basic representation of a document is based on a One-hot encoding of the tokenized text. In other words, every text is represented as a vector of 0’s and only one ‘1’ in the position given by the index of the words in te text, according to the ones assigned during tokenization. The length of the vector corresponds to the parameter num_words, which is the size of the dictionary.
Based on a bag of words representation a whole paragraph or document could be codified as a vector of num_words positions, where the position \(i\) accounts for the number of times that the word \(i\) appeared in the text. Usually, such vector is normalized with respecto the number of words in the text, this is call term-frecuency representation. However, it is more common to use the tf-idf representetation.
from sklearn.feature_extraction.text import CountVectorizer
synopses = []
synopses.append('ejemplo de texto a ser procesado')
synopses.append('algunos ejemplos puenden ser más complejos que otros ejemplos')
synopses.append('No se si sea posible dar algunos ejemplos')
#define vectorizer parameters
count_vectorizer = CountVectorizer(max_df=0.9, max_features=200,
min_df=0.1)
%time count_matrix = count_vectorizer.fit_transform(synopses) #fit the vectorizer to synopses
print(count_matrix.shape)
count_matrix.toarray()
CPU times: user 1.98 ms, sys: 244 µs, total: 2.22 ms
Wall time: 2.2 ms
(3, 18)
array([[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 0, 0, 0, 2, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0],
[1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0]])
count_vectorizer.get_feature_names_out()
array(['algunos', 'complejos', 'dar', 'de', 'ejemplo', 'ejemplos', 'más',
'no', 'otros', 'posible', 'procesado', 'puenden', 'que', 'se',
'sea', 'ser', 'si', 'texto'], dtype=object)
Stemming#
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer('spanish')
synopsesStem = []
for sentence in synopses:
synopsesStem.append(" ".join([stemmer.stem(word) for word in sentence.split()]))
#define vectorizer parameters
count_vectorizer = CountVectorizer(max_df=1.0, max_features=200,
min_df=0.1)
count_matrix = count_vectorizer.fit_transform(synopsesStem) #fit the vectorizer to synopses
count_vectorizer.get_feature_names_out()
array(['algun', 'complej', 'dar', 'de', 'ejempl', 'mas', 'no', 'otros',
'posibl', 'proces', 'puend', 'que', 'se', 'sea', 'ser', 'si',
'text'], dtype=object)
print(count_matrix.shape)
count_matrix.toarray()
(3, 17)
array([[0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 0, 0, 2, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0],
[1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0]])
This provides a matrix with a row per document and a column per word in the dictionary. The position [\(i\), \(j\)] corresponds to the number of times the word \(j\) appeared in the document \(i\).
Home work: Read about the difference between steeming and lemmatization
tf-idf representation#
This stands for term frequency and inverse document frequency. The tf-idf weighting scheme assigns to term \(t\) a weight in document \(d\) given by
Term Frequency (tf): gives us the frequency of the word in each document in the corpus. It is the ratio of number of times the word appears in a document compared to the total number of words in that document. It increases as the number of occurrences of that word within the document increases. Each document has its own tf.
Inverse Data Frequency (idf): used to calculate the weight of rare words across all documents in the corpus. The words that occur rarely in the corpus have a high IDF score. It is given by the equation below.
In other words, \(\mbox{tf-idf}_{t,d}\) assigns to term \(t\) a weight in document \(d\) that is
highest when \(t\) occurs many times within a small number of documents (thus lending high discriminating power to those documents);
lower when the term occurs fewer times in a document, or occurs in many documents (thus offering a less pronounced relevance signal);
lowest when the term occurs in virtually all documents.
from sklearn.feature_extraction.text import TfidfVectorizer
#define vectorizer parameters
tfidf_vectorizer = TfidfVectorizer(max_df=1.0, max_features=200,
min_df=0.1, stop_words=stopwords,
use_idf=True, tokenizer= word_tokenize, ngram_range=(1,3))
%time tfidf_matrix = tfidf_vectorizer.fit_transform(synopsesStem) #fit the vectorizer to synopses
print(tfidf_matrix.shape)
print(tfidf_matrix.toarray())
CPU times: user 24.5 ms, sys: 2.87 ms, total: 27.4 ms
Wall time: 27.4 ms
(3, 33)
[[0. 0. 0. 0. 0. 0.
0. 0. 0.20977061 0. 0. 0.35517252
0.35517252 0. 0. 0. 0. 0.
0. 0.35517252 0. 0. 0. 0.27011786
0. 0. 0.35517252 0. 0. 0.
0.35517252 0.35517252 0.35517252]
[0.18936073 0.18936073 0.2489866 0.2489866 0.2489866 0.
0. 0. 0.294111 0.2489866 0.2489866 0.
0. 0.2489866 0.2489866 0.2489866 0. 0.
0. 0. 0.2489866 0.2489866 0.2489866 0.18936073
0.2489866 0.2489866 0. 0. 0. 0.
0. 0. 0. ]
[0.23464049 0.23464049 0. 0. 0. 0.30852405
0.30852405 0.30852405 0.18221927 0. 0. 0.
0. 0. 0. 0. 0.30852405 0.30852405
0.30852405 0. 0. 0. 0. 0.
0. 0. 0. 0.30852405 0.30852405 0.30852405
0. 0. 0. ]]
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/feature_extraction/text.py:517: UserWarning: The parameter 'token_pattern' will not be used since 'tokenizer' is not None'
warnings.warn(
print(dict(zip(tfidf_vectorizer.get_feature_names_out(), tfidf_vectorizer.idf_)))
{'algun': np.float64(1.2876820724517808), 'algun ejempl': np.float64(1.2876820724517808), 'algun ejempl puend': np.float64(1.6931471805599454), 'complej': np.float64(1.6931471805599454), 'complej ejempl': np.float64(1.6931471805599454), 'dar': np.float64(1.6931471805599454), 'dar algun': np.float64(1.6931471805599454), 'dar algun ejempl': np.float64(1.6931471805599454), 'ejempl': np.float64(1.0), 'ejempl puend': np.float64(1.6931471805599454), 'ejempl puend ser': np.float64(1.6931471805599454), 'ejempl text': np.float64(1.6931471805599454), 'ejempl text ser': np.float64(1.6931471805599454), 'mas': np.float64(1.6931471805599454), 'mas complej': np.float64(1.6931471805599454), 'mas complej ejempl': np.float64(1.6931471805599454), 'posibl': np.float64(1.6931471805599454), 'posibl dar': np.float64(1.6931471805599454), 'posibl dar algun': np.float64(1.6931471805599454), 'proces': np.float64(1.6931471805599454), 'puend': np.float64(1.6931471805599454), 'puend ser': np.float64(1.6931471805599454), 'puend ser mas': np.float64(1.6931471805599454), 'ser': np.float64(1.2876820724517808), 'ser mas': np.float64(1.6931471805599454), 'ser mas complej': np.float64(1.6931471805599454), 'ser proces': np.float64(1.6931471805599454), 'si': np.float64(1.6931471805599454), 'si posibl': np.float64(1.6931471805599454), 'si posibl dar': np.float64(1.6931471805599454), 'text': np.float64(1.6931471805599454), 'text ser': np.float64(1.6931471805599454), 'text ser proces': np.float64(1.6931471805599454)}
Word embeddings#
word2vec#
There exist several alternatives to represent the words in a different way. In most of the cases, those techniques try to take advantage on the semantic similarity of the words. Such similarity can be sintacmatic or paradigmatic. Paradigmatic similarity refers to the interchange of words. On the other hand, sintacmatic similarity refers to co-ocurrence.
Two of the most used techniques are based on Neural Network representations:
skip-gram model: This architecture is designed to predict the context given a word
Continuous Bag of Words (CBOW): The CBOW model architecture tries to predict the current target word (the center word) based on the source context words (surrounding words).
from IPython.display import Image, display
Image(filename='local/imgs/word2vec.png', width=800)
#
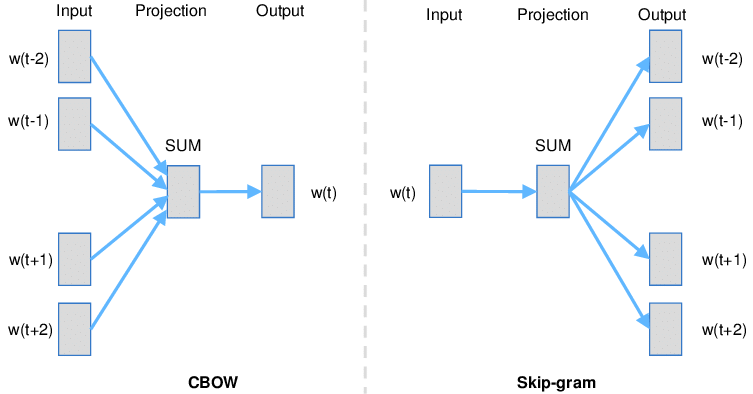
According to Mikolov (https://arxiv.org/pdf/1310.4546.pdf):
Skip-gram: works well with small amount of the training data, represents well even rare words or phrases.
CBOW: several times faster to train than the skip-gram, slightly better accuracy for the frequent words
Alternative activation functions#
One of the problems with word2vec architecture is the large number of outputs, which increases a lot the computational cost. In order to tackle this problem, there are two approaches:
Hierarchical softmax: This use a binary tree to represent the probabilities of the words at the output layer an reduces the computational cost logarithmically. The output layer is replaced by sigmoid functions representing the decision in every node of the tree.
https://www.iro.umontreal.ca/~lisa/pointeurs/hierarchical-nnlm-aistats05.pdf
Negative sampling: Negative sampling addresses the computational problem by having each training sample only modify a small percentage of the weights, rather than all of them.
https://arxiv.org/pdf/1310.4546.pdf
A = Image(filename='local/imgs/Softmax.png', width=600)
B = Image(filename='local/imgs/HSoftmax.png', width=600)
display(A, B)
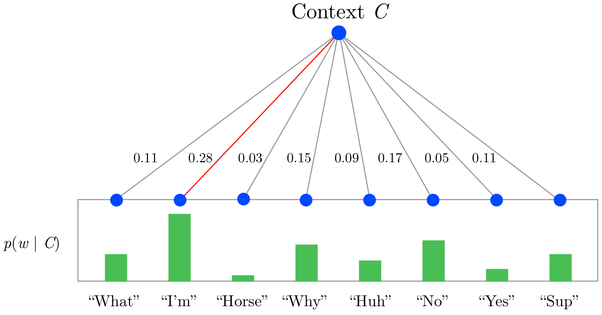
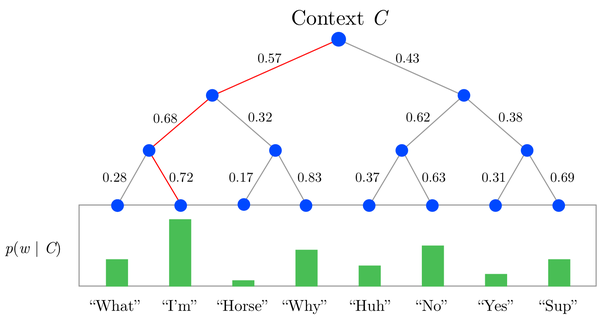
There is a nice library called Gensim for training CBOW and Skip-gram models, but it is not compatible with the current versions of NumPy and SciPy. A new version is in process to be leaveraged, so it is worth to take a look at it.
Let’s build a word2vec model using tf#
import bs4 as bs
import urllib.request
import re
import nltk
url = 'https://en.wikipedia.org/wiki/Artificial_intelligence'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
req = urllib.request.Request(url, headers=headers)
try:
with urllib.request.urlopen(req) as response:
# Read the content of the response
article = response.read()
parsed_article = bs.BeautifulSoup(article,'lxml')
paragraphs = parsed_article.find_all('p')
article_text = ""
for p in paragraphs:
article_text += p.text
except urllib.error.HTTPError as e:
print(f"HTTP Error: {e.code} - {e.reason}")
except urllib.error.URLError as e:
print(f"URL Error: {e.reason}")
# Cleaing the text
processed_article = article_text.lower()
processed_article = re.sub('[^a-zA-Z]', ' ', processed_article )
processed_article = re.sub(r'\s+', ' ', processed_article)
# Preparing the dataset
all_sentences = nltk.sent_tokenize(processed_article)
all_words = [nltk.word_tokenize(sent) for sent in all_sentences]
# Removing Stop Words
from nltk.corpus import stopwords
for i in range(len(all_words)):
all_words = [[' '.join(w for w in all_words[i] if w not in stopwords.words('english'))]]
from local.lib.mlutils import prepare_text_for_cbow, generate_context_word_pairs
wids, vocab_size, embed_size, window_size, id2word, word2id = prepare_text_for_cbow(all_words)
Vocabulary Size: 2944
Vocabulary Sample: [('ai', 1), ('intelligence', 2), ('learning', 3), ('used', 4), ('data', 5), ('artificial', 6), ('human', 7), ('machine', 8), ('research', 9), ('use', 10)]
# Test this out for some samples
i = 0
for x, y in generate_context_word_pairs(corpus=[wids], window_size=window_size, vocab_size=vocab_size):
if 0 not in x[0]:
print('Context (X):', [id2word[w] for w in x[0]], '-> Target (Y):', id2word[np.argwhere(y[0])[0][0]])
if i == 10:
break
i += 1
Context (X): ['artificial', 'intelligence', 'capability', 'computational'] -> Target (Y): ai
Context (X): ['intelligence', 'ai', 'computational', 'systems'] -> Target (Y): capability
Context (X): ['ai', 'capability', 'systems', 'perform'] -> Target (Y): computational
Context (X): ['capability', 'computational', 'perform', 'tasks'] -> Target (Y): systems
Context (X): ['computational', 'systems', 'tasks', 'typically'] -> Target (Y): perform
Context (X): ['systems', 'perform', 'typically', 'associated'] -> Target (Y): tasks
Context (X): ['perform', 'tasks', 'associated', 'human'] -> Target (Y): typically
Context (X): ['tasks', 'typically', 'human', 'intelligence'] -> Target (Y): associated
Context (X): ['typically', 'associated', 'intelligence', 'learning'] -> Target (Y): human
Context (X): ['associated', 'human', 'learning', 'reasoning'] -> Target (Y): intelligence
Context (X): ['human', 'intelligence', 'reasoning', 'problem'] -> Target (Y): learning
import tensorflow.keras.backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Lambda, Input
# build the CBOW architecture
cbow = Sequential()
cbow.add(Input(shape=(window_size*2,)))
cbow.add(Embedding(input_dim=vocab_size, output_dim=embed_size))
cbow.add(Lambda(lambda x: k.mean(x, axis=1), output_shape=(embed_size,)))
cbow.add(Dense(vocab_size, activation='softmax'))
cbow.compile(loss='categorical_crossentropy', optimizer='rmsprop')
cbow.summary()
Model: "sequential_6"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ embedding_5 (Embedding) │ (None, 12, 10) │ 29,440 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ lambda_5 (Lambda) │ (None, 10) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_4 (Dense) │ (None, 2944) │ 32,384 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 61,824 (241.50 KB)
Trainable params: 61,824 (241.50 KB)
Non-trainable params: 0 (0.00 B)
window_size = 6
for epoch in range(1,20):
loss = 0
i = 0
for x, y in generate_context_word_pairs(corpus=[wids], window_size=window_size, vocab_size=vocab_size):
i+=1
loss += cbow.train_on_batch(x,y)
if i % 100000 == 0:
print('Processed {} (context, word) pairs'.format(i))
print('Epoch:', epoch, '\tLoss:', loss)
print()
Epoch: 1 Loss: 63097.152
Epoch: 2 Loss: 62350.246
Epoch: 3 Loss: 62112.46
Epoch: 4 Loss: 62031.008
Epoch: 5 Loss: 61987.746
Epoch: 6 Loss: 61957.742
Epoch: 7 Loss: 61933.617
Epoch: 8 Loss: 61911.668
Epoch: 9 Loss: 61898.01
Epoch: 10 Loss: 61879.707
Epoch: 11 Loss: 61870.39
Epoch: 12 Loss: 61854.01
Epoch: 13 Loss: 61845.18
Epoch: 14 Loss: 61836.42
Epoch: 15 Loss: 61822.066
Epoch: 16 Loss: 61815.332
Epoch: 17 Loss: 61812.426
Epoch: 18 Loss: 61804.188
Epoch: 19 Loss: 61791.52
weights = cbow.get_weights()[0]
weights = weights[1:]
print(weights.shape)
(2943, 10)
from sklearn.metrics.pairwise import euclidean_distances
# compute pairwise distance matrix
distance_matrix = euclidean_distances(weights)
print(distance_matrix.shape)
# view contextually similar words
similar_words = {
search_term: [
(id2word[idx+1], distance_matrix[word2id[search_term]-1][idx])
for idx in distance_matrix[word2id[search_term]-1].argsort()[1:6]
]
for search_term in ["intelligence"]
}
similar_words
(2943, 2943)
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: divide by zero encountered in matmul
ret = a @ b
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: overflow encountered in matmul
ret = a @ b
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: invalid value encountered in matmul
ret = a @ b
{'intelligence': [('artificial', np.float32(1.1204317)),
('human', np.float32(1.3073528)),
('machines', np.float32(1.3116813)),
('field', np.float32(1.4723947)),
('information', np.float32(1.6915356))]}
TerminosDeInteres = ['ai','artificial','intelligence', 'statistics', 'economics', 'mathematics','data', 'scientific', 'reinforcement','learning','mining','processing','databases']
wordvecs = np.stack([weights[word2id[search_term]-1] for search_term in TerminosDeInteres])
wordvecs.shape
(13, 10)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(all_words[0])
CountTerminosDeInteres = np.zeros(len(TerminosDeInteres))
for i in range(len(TerminosDeInteres)):
CountTerminosDeInteres[i] = tokenizer.word_counts[TerminosDeInteres[i]]
from sklearn.manifold import MDS
embedding = MDS(n_components=2)
X_embedded = embedding.fit_transform(wordvecs)
fig, ax = plt.subplots(figsize=(12,12))
ax.scatter(X_embedded[:,0], X_embedded[:,1], s=CountTerminosDeInteres, alpha=0.3)
for i, txt in enumerate(TerminosDeInteres):
ax.annotate(txt, (X_embedded[i,0], X_embedded[i,1]))
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: divide by zero encountered in matmul
ret = a @ b
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: overflow encountered in matmul
ret = a @ b
/Users/jdariasl/Documents/MaterialesClase/Fund_Deep_Learning/.venv/lib/python3.9/site-packages/sklearn/utils/extmath.py:203: RuntimeWarning: invalid value encountered in matmul
ret = a @ b
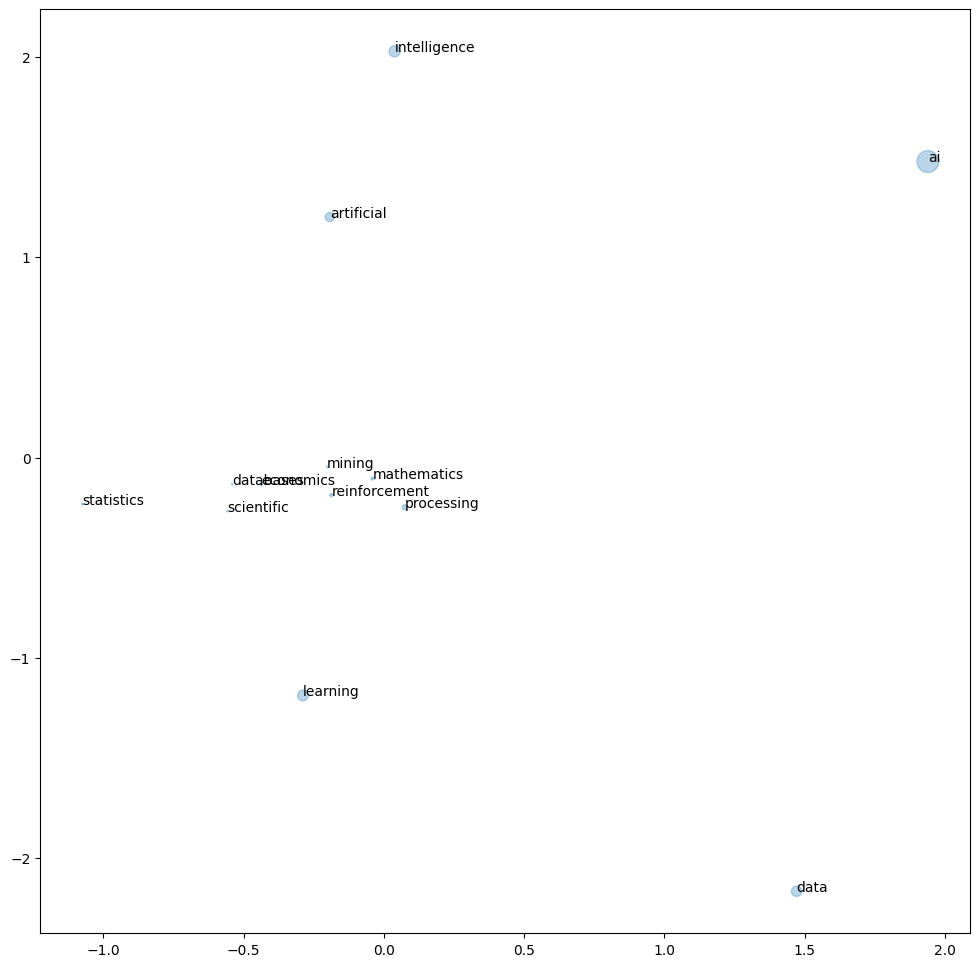
Skip-gram implementation in tf
Training objective:
where \(c\) is the size of the training context. The basic formulation defines the probability as
where \({\bf{v}}_w\) is the vector representation of the word \(w\) and \(W\) is the size of the dictionary.
Take a look at the implementation available on this link
There are other two widely used representations based on Matrix factorization:#
These methods utilize low-rank approximations to decompose large matrices that capture statistical information about a corpus. That means that this methods are unsupervised in comparison to skip-gram and CBOW that are supervised.
Latent Semantic Analysis: Based on tf-idf representation http://lsa.colorado.edu/papers/dp1.LSAintro.pdf
Global vectos (GoVe): Based on the co-occurrence matrix https://nlp.stanford.edu/pubs/glove.pdf
Different pretrained GloVe embeddings can be download from here. The lightest file is more than 800 Mb, so a tutorial for its use can be found in the following link
#import gensim.downloader
#print(list(gensim.downloader.info()['models'].keys()))
# Download the "glove-twitter-25" embeddings
#glove_vectors = gensim.downloader.load('glove-twitter-25')
Keras Embedding#
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Input
model = Sequential()
model.add(Input(shape=(3,)))
model.add(Embedding(input_dim=1000, output_dim = 4))
model.compile(optimizer = 'adam', loss='mse')
print(model.predict(np.array([[4,8,3]])))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step
[[[-0.02371303 0.00716837 -0.02285376 0.04179534]
[-0.02503325 -0.03807782 -0.02270105 0.02248449]
[ 0.04261405 0.0298858 -0.00957584 -0.04253836]]]
Transfer learning!#
The embedding weights can be replaced by pretrained word2vec weights and used into the the network:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
inputs = Input(shape=(3,))
e = Embedding(input_dim=100, output_dim = 4, weights = [np.random.normal(0,1,size=(100,4))],trainable = False)(inputs)
model = Model(inputs=inputs,outputs=e)
model.compile(optimizer = 'adam', loss='mse')
print(model.predict(np.array([[4,8,3]])))
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step
[[[-1.69751 -0.16846594 0.01590205 0.4779847 ]
[-1.4023608 -1.5816872 -0.49606568 1.2519339 ]
[ 0.64782345 2.1656923 0.3370885 0.6460906 ]]]
model.summary()
Model: "functional_15"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer_7 (InputLayer) │ (None, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ embedding_8 (Embedding) │ (None, 3, 4) │ 400 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 400 (1.56 KB)
Trainable params: 0 (0.00 B)
Non-trainable params: 400 (1.56 KB)