
LAB 04.02 - Buiding Datasets#
!wget --no-cache -O init.py -q https://raw.githubusercontent.com/rramosp/ai4eng.v1/main/content/init.py
import init; init.init(force_download=False); init.get_weblink()
init.endpoint
from local.lib.rlxmoocapi import submit, session
session.LoginSequence(endpoint=init.endpoint, course_id=init.course_id, lab_id="L04.02", varname="student");
Understand the ASHRAE Energy Prediction in Kaggle#
Follow this link: https://www.kaggle.com/c/ashrae-energy-prediction, register for the task and download the data.
In particular, understand:
The machine learning task they define (what they want to predict)
How the data is provided
The structure and relation between the files
train.csv,weather_train.csvandbuilding_metadata.csv
Task 1: Build a training dataset#
Execute the cell below and you will be given a building_id and a date. You will have to:
Build a table containing one row per hour and the following columns only for that building_id and date: ‘meter_reading’, ‘site_id’, ‘air_temperature’, ‘cloud_coverage’, ‘dew_temperature’, ‘precip_depth_1_hr’, ‘sea_level_pressure’, ‘wind_direction’, ‘wind_speed’, ‘square_feet’, ‘year_built’ Note that you will have to gather this information from the different csv sources.
use only measures with
meter=0Fill any missing values with zero.
Extract the column of the target variable and sum all values.
Sum all the values of the rest of the columns.
Fill in those values in the variables below.
Submit your answer.
Observe that, with this dataset, we could train a model to make predictions of the target variable, taking the rest of the variables as input.
For instance, for building number 900, on 2016-02-01:
there are 24 records
the sum of all values of the target variable is 4941 (cropping decimals)
the sum of all values of the rest of the variables is 2705422 (cropping decimals)
from IPython.display import Image
from local.lib import labutils
import numpy as np
bid, date = labutils.biddate_for_student(student.user_id)
print ("your building_id", bid)
print ("your date ", date)
provide your answer here, drop the decimals#
# target variable sum
sumY =
# input variables sum
sumX =
sumX, sumY
submit your answer
student.submit_task(globals(), task_id="task_01");
Task 2. Time series missing data fix#
Observe how we can fill in missing data in a time series, by simply repeating the last seen value in the missing places.
Image("local/imgs/timeseries-ffill.png")
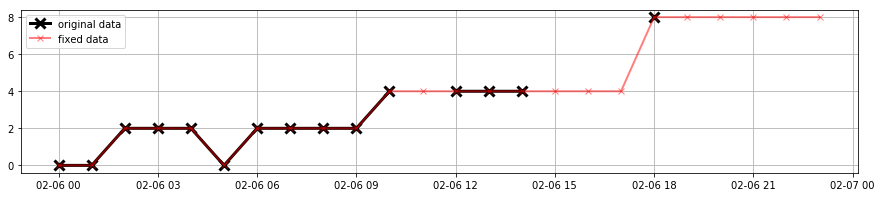
Using the weather data from the ASHRAE Kaggle competition that you must have downloaded in the previous task you will have to:
Extract the time series for the variable
cloud_coveragefor site_id=3 and for the date assigned to you (execute the cell below). This time series will have 24 values (including missing values).Fill in the missing data by repeating the last seen value as in the example above
Report the time series as a Pyton list in the variable
fixed_tsbelow
Again, use any tool of your choice to generate your result
from local.lib import labutils
_, date = labutils.biddate_for_student(student.user_id)
print ("your date ", date)
fill in your fixed time series#
# for instance
# fixed_ts = [6,6,6,4,4,5,6,7,7,7,6,6,6,5,4,3,2,2,1,1,1,2,3,4]
fixed_ts = [ ]
submit your answer
student.submit_task(globals(), task_id="task_02");
Task 3. Build a time series predictive dataset#
You will now build a predictive dataset for a single time series. This dataset can later be used with predictive models. The machine learning task we will try to adress is the following:
Given three consecutive points of a time series, we want a model to predict the next one.
Starting from a time series (a list of of \(n\) numbers) you will have to build a dataset such as in the following example
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
ts = np.r_[44, 45, 42, 38, 47, 45, 46, 44, 47, 52, 53, 48, 46, 42, 42, 34, 30, 27, 24, 24]
plt.figure(figsize=(10,2))
plt.xticks(range(len(ts)), range(len(ts)))
plt.grid();
plt.plot(ts)
print (ts)
[44 45 42 38 47 45 46 44 47 52 53 48 46 42 42 34 30 27 24 24]
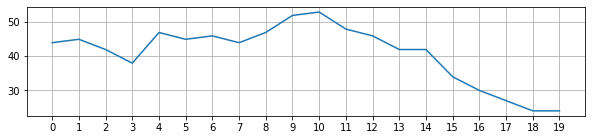
dataset:
[[[44, 45, 42], 38],
[[45, 42, 38], 47],
[[42, 38, 47], 45],
[[38, 47, 45], 46],
[[47, 45, 46], 44],
[[45, 46, 44], 47],
[[46, 44, 47], 52],
[[44, 47, 52], 53],
[[47, 52, 53], 48],
[[52, 53, 48], 46],
[[53, 48, 46], 42],
[[48, 46, 42], 42],
[[46, 42, 42], 34],
[[42, 42, 34], 30],
[[42, 34, 30], 27],
[[34, 30, 27], 24],
[[30, 27, 24], 24]]
observe that each line in the dataset represents one input-output pair, like a sliding window over the time series.
We created two components:
a matrix \(X\) of dimensions
(len(ts)-n,3)gathering all inputs, in the case above with dimensions(17,3)a vector \(y\) of dimension
(len(ts)-n)gathering each corresponding expected output, in the case above with dimensions(17).
In this task, you will have to:
Take the time series you created in the previous task, where you fixed the missing values.
Build \(X\), \(y\) such as above with \(n=3\). If your time series has 24 data points, then X dimensions will be (21,3) and y dimensions will be (21)
Again, use any tool of your choice to generate your result.
fill in your answer#
X = [ [ , , ],
[ , , ],
[ , , ]
....
]
y = [ , , , , ... ]
submit your answer
student.submit_task(globals(), task_id="task_03");